컴퓨터공학 💻/알고리즘 분석
[알고리즘] 그래프 탐색 알고리즘
- -
깊이 우선 탐색(DFS: depth first search)

• 한 방향으로 갈 수 있을 때까지 가다가 더 이상 갈 수 없게 되면 가장 가까운 갈림길로 돌아와서 이 곳으로부터 다른 방향으로 다시 탐색 진행
• 되돌아가기 위해서는 스택 필요 (재귀 함수 호출로 묵시적인 스택 이용 가능)
실행단계
알고리즘
DFS(G) {
for each v ∈ V
visited[v] ← NO;
for each v ∈ V
if (visited[v] = NO) then aDFS(v);
}
aDFS (v) {
visited[v] ← YES;
for each u ∈ L(v) # L(v) : 정점 v의 인접 리스트
if (visited[u] = NO) then aDFS(u);
}시간 복잡도 O(V(V-1)), Θ(|V|+|E|)
- 첫번째 for문 수행시간 = V수
- 두번째 for문 수행시간 = V수
- aDFS(v) 수행시간 = V수
- for each 수행시간 = V-1 = 2E (간선수의 2배)
너비 우선 탐색(BFS: breath first search)
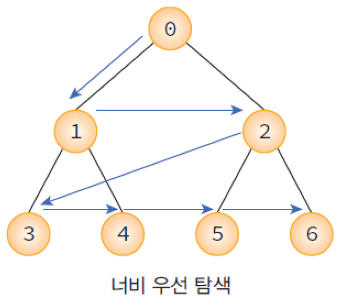
• 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법
– 큐를 사용하여 구현
실행단계

알고리즘
BFS(G, s) {
for each v ∈ V
visited[v] ← NO;
visited[s] ← YES; # s: 시작 정점
enqueue(Q, s); # Q: 큐
while (Q ≠ ϕ) {
u ← dequeue(Q);
for each v ∈ L(u) # L(u): 정점 u의 인접 리스트
if (visited[v] = NO) then
visited[v] ← YES;
enqueue(Q, v);
}
}시간 복잡도 O(V(V-1)), Θ(|V|+|E|)
- for each 수행시간 = V수
- visited[s] <- YES = 상수시간
- enqueue(Q, s); = 상수시간
- while = V수
- for each = 2E (간선수의 2배)
-if = 2E
최소신장트리 Minimum Spanning Tree
• 조건 : 무향 연결 그래프
• 트리
– 싸이클이 없는 연결 그래프
– n 개의 정점을 가진 트리는 항상 n-1개의 간선을 갖는다
• 그래프 G의 신장트리
– G의 정점들과 간선들로만 구성된 트리
• G의 최소신장트리
– G의 신장트리들 중 간선의 합이 최소인 신장트리
프림 알고리즘
Prim 알고리즘은 그리디greedy 알고리즘의 일종이며 그리디 알고리즘으로 최적해를 보장하는 드문 예이다.
프림 알고리즘1
Prim (G, r) {
S ←Ф ;
정점 r을 방문되었다고 표시하고, 집합 S에 포함시킨다;
while (S≠V) {
S에서 V-S를 연결하는 간선들 중 최소길이의 간선 (x, y) 를 찾는다; ▷ (x∈S, y∈V-S)
정점 y를 방문되었다고 표시하고, 집합 S에 포함시킨다;
}
}
# 수행 시간: O(|E|log|V|) # 힙 이용
프림 알고리즘2
# 배열을 이용할 때의 수행시간 분석 : O(V^2)
Prim(G, r) {
# G=(V, E): 주어진 그래프
# r: 시작으로 삼을 정점
# w_uv: 정점v에서 u까지의 거리
S <- Ф; # S: 정점 집합 # 수행시간: 1
for each u∈V # 수행시간: V
d_u <- ∞;
d_r <- 0;
while(S != V) { # 수행시간: V or n
u <- extractMin(V-S, d); # 수행시간: V * V
S <- S ∪ {u}; # 수행시간: V
for each v∈L(u) # L(u) : u로부터 연결된 정점들의 집합 # 수행시간: 2E
if (v∈V-S && w_uv < d_v) then d_v ← w_uv; # 수행시간: 2E
}
}
extractMin(Q, d) { # 수행시간: V
집합 Q에서 d값이 가장 작은 정점 u를 리턴한다;
}
# 힙을 이용할 때의 수행시간 분석 : O(ElogV)
Prim(G, r) {
# G=(V, E): 주어진 그래프
# r: 시작으로 삼을 정점
# w_uv: 정점v에서 u까지의 거리
S <- Ф; # S: 정점 집합 # 수행시간: 1
for each u∈V # 수행시간: V
d_u <- ∞;
d_r <- 0;
while(S != V) { # 수행시간: V or n
u <- extractMin(V-S, d); # 수행시간: V * logV
S <- S ∪ {u}; # 수행시간: V
for each v∈L(u) # L(u) : u로부터 연결된 정점들의 집합 # 수행시간: 2E
if (v∈V-S && w_uv < d_v) # 수행시간: 2E
then d_v ← w_uv; # 수행시간: 2E * logV (heapify)
}
}
extractMin(Q, d) { # 수행시간: logV
집합 Q에서 d값이 가장 작은 정점 u를 리턴한다;
}
수행과정


[예제] 다음 그래프들에 대해서 슬라이드 24의 Prim(G,r)을 수행하는 과정을 나타내라. For문은 index가 작은 것부터 수행된다고 가정한다. 집합Q중 거리d가 같은 두 정점 있을 경우 index가 작은 정점이 선택된다고 가정한다. while문이 끝날 때마다 신장트리를 그리고 배열d[],배열tree[],집합Q의 상태를 나타내라. While문은 총 몇 번 도는가?



크루스칼 알고리즘

(a) make-set 7번 수행
(b) find-set 2번, union 1번 수행
. . .

(f) find-set 2번 수행
알고리즘
Kruskal (G, r) { # 수행시간: O(ElogV)
# T : 신장트리
1. T ← Ф ; # 수행시간: 1
2. 단 하나의 정점만으로 이루어진 n 개의 집합을 초기화한다; # 수행시간: V or n
3. 간선 집합 Q(=E)를 가중치가 작은 순으로 정렬한다; # 수행시간: ElogE (E개를 각각 정렬)
4. while (T의 간선수 < n-1) { # 수행시간: 최대 E
Q에서 최소비용 간선 (u, v)를 제거한다; # 수행시간: E * 1
정점 u와 정점 v가 서로 다른 집합에 속하면 { # 수행시간: E * logV
두 집합을 하나로 합친다; # 수행시간: E * logV
T ← T∪{(u, v)}; # 수행시간: E * 1
}
}
}

위상정렬
• 조건
– 싸이클이 없는 유향 그래프
• 위상정렬
– 모든 정점을 일렬로 나열하되
– 정점 x에서 정점 y로 가는 간선이 있으면
– x는 반드시 y보다 앞에 위치한다
– 일반적으로 임의의 유향 그래프에 대해 복수의 위상 순서가 존재한다
알고리즘1
topologicalSort1(G) {
for ← 1 to n { # V
진입간선이 없는 정점 u를 선택한다; # 1 * V
A[i] ← u; # 1 * V
정점 u와, u의 진출간선을 모두 제거한다; # V + E
}
# 이 시점에 배열 A[1…n]에는 정점들이 위상정렬되어 있다
}
Θ(|V|+|E|)알고리즘2
topologicalSort2(G) {
for each v∈V # V
visited[v] ← NO; # 1 * V
for each v∈V # 정점의 순서는 무관 # V
if (visited[v] = NO) then DFS-TS(v); # if조건안 -> 1 * V
}
DFS-TS(v) { # V
visited[v] ← YES; # 1 * V
for each x∈L(v) ▷ L(v): v의 인접 리스트 # E
if (visited[x] = NO) then DFS-TS(x) ; # if조건안 -> 1 * E
연결 리스트 R의 맨 앞에 정점 v를 삽입한다; # 1 * V
}
# Θ(|V|+|E|)
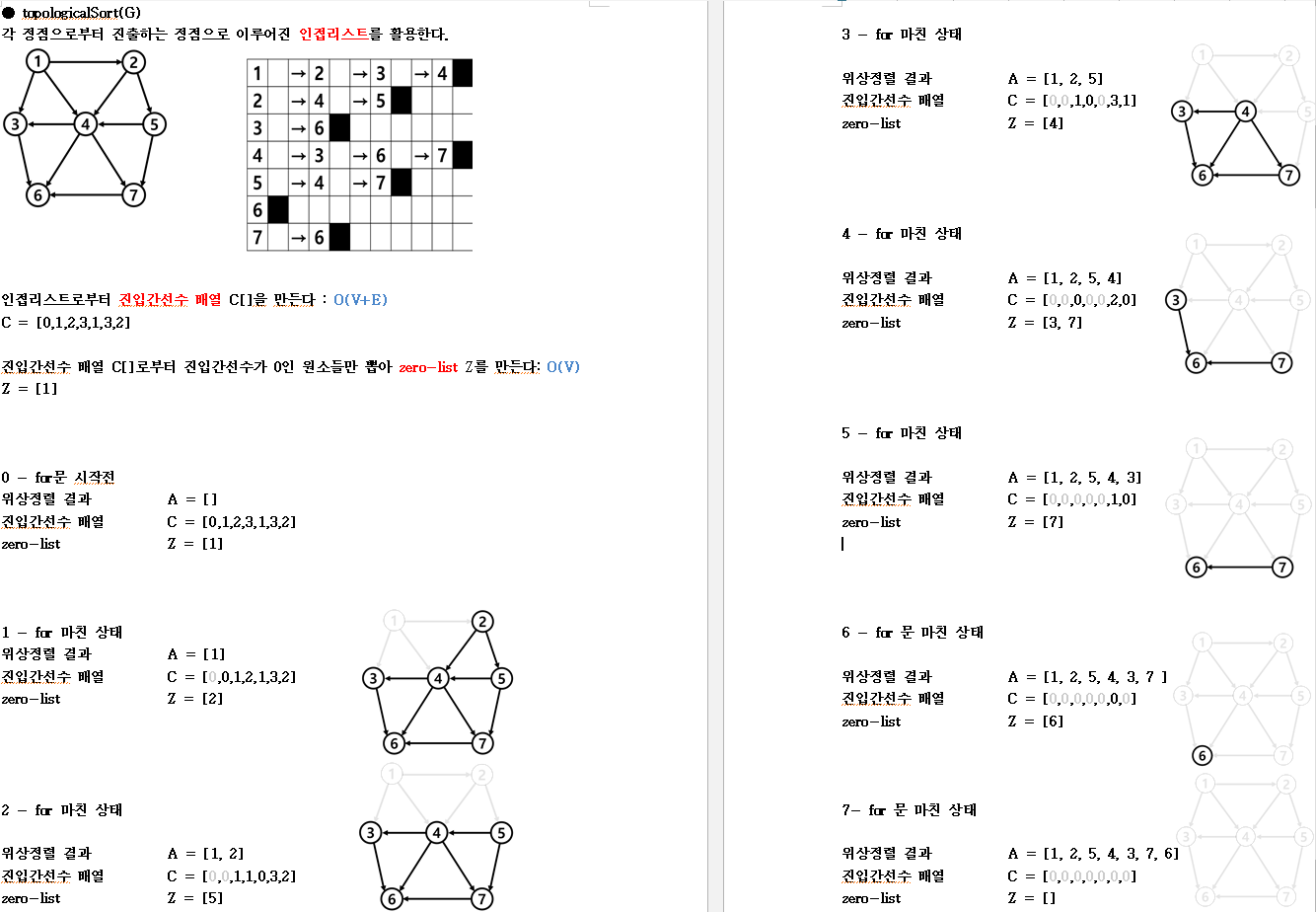

자료참조 - 쉽게 배우는 알고리즘 · 관계 중심의 사고법 / 문병로
Contents
소중한 공감 감사합니다