컴퓨터공학 💻/딥러닝
[딥러닝] Activation Function과 Vanishing Gradient Problem
- -
Activation Function과 Vanishing Gradient Problem
Activation Function은 간단하게 어떤 Input 데이터가 들어왔을 때 값을 normalize하여 active할지 inactive할지를 결정하는 함수입니다. 이러한 Activation Function에는 여러가지 함수가 존재하며 2가지 범주로 Output Layer에서 사용하는 함수와 Hidden Layer에서 사용하는 함수가 있습니다.
Linear

들어온 Input 데이터에 대해서 선형 연산된 값을 그대로 출력하는 함수입니다.
Sigmoid
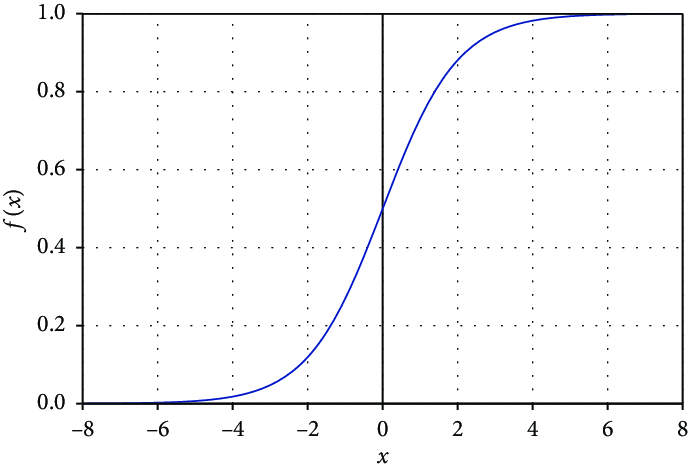
질문에 대한 답이 Yes일 확률을 계산하는 확률 분포함수이며 0~1 사이의 값을 출력합니다. 일반적으로 2개의 카테고리를 예측할 때 Output layer에서 사용하되 중간의 Hidden Layer에서도 사용합니다.
Hidden Layer로 기능하려면 normalize, 즉 값의 분포를 줄이는 역할을 하는 지, non-linear 한 지 여부를 고려해야 하는데 사용하는 목적은 모든 Activation Function이 non-linear한 특징을 가지기 때문에 값의 분포도를 줄이고 MLP들이 다양한 추론을 할 수 있도록 서브 역할을 같이 수행하는 것입니다.
Softmax

n개의 다중 카테고리일 때 Output Layer에서 사용합니다. n개의 요소를 갖는 확률 벡터이며 각 요소의 값이 0~1 사이이고 전체이 합이 1입니다.
만약 카테고리가 2개라면, 예를 들어 어떤 사진이 Dog일 확률이 0.7이라면 Cat일 확률은 자동으로 0.3입니다. 그런데 여기에 Human 카테고리를 추가하게 되면 Cat일 확률을 0.3이라고 할 때 Human과 Dog일 확률을 계산할 수 없게됩니다. 그래서 각 다중 카테고리의 확률 값을 모두 계산해야 하는 상황에서는 Softmax 함수를 사용합니다.
tanh

feature 값의 범위를 줄여주는 역할을 하며 주로 Hidden layer에서만 사용하고 -1~1사이의 값을 출력합니다. 반드시 -1~1사이 혹은 -1과 1의 값으로만 출력해야하는 데이터(의료, 금융 관련 데이터, 이미지 생성)에서 사용합니다.
Relu
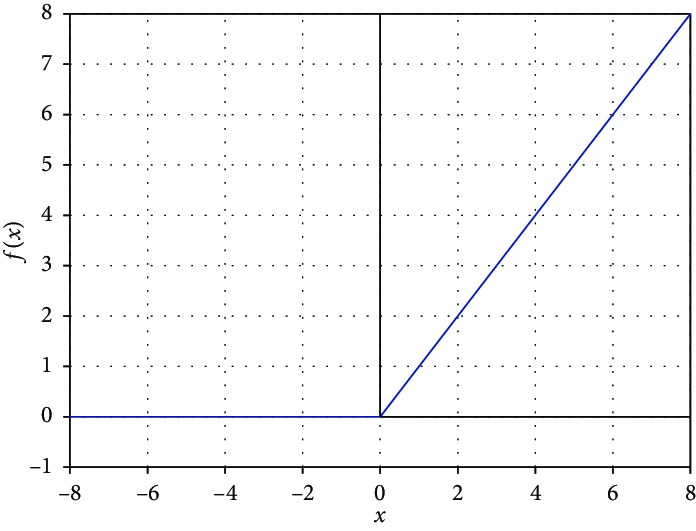
Layer가 매우 많은, 다중 카테고리일 때 사용합니다. 입력 값이 < 0 이면 0, 입력 값이 > 0 이면 Linear로 동작합니다.
sigmoid, tanh 보다 학습속도가 빠르다는 장점이 있습니다. 또한 다중 레이어에서 발생할 수 있는 Vanishing Gradient Problem을 해결하는데 큰 도움이 됩니다.
Vanishing Gradient Problem이 문제가 되는 이유
레이어가 엄청나게 많을 때 발생하는 문제입니다. Output Layer에서 출력된 예측값과 정답값을 비교해서 계산된 Loss를 토대로 optimizer는 weight값을 조정하려 할 때 어떤 weight가 문제였는지 추적이 힘들어집니다.
대표적으로 문제가 발생하는 tanh 그래프를 보시면 Input이 -1일 때와 1일 때의 값의 차이는 매우 큽니다. 하지만 2와 4의 차이는 거의 미미하죠. 분명 Input 값의 차이는 절댓값 2만큼으로 동일하나 결괏값의 차이가 다릅니다. 조금 더 극단적으로, input이 5일 때와 5,000,000 일 때의 결괏값의 차이는 0이라고 봐도 무방합니다. 그래서 레이어가 많아질수록 문제가 되는 weight값을 찾기가 힘든 것입니다.
이러한 면에서 non-linear한 특징과 linear한 특징을 동시에 가지고 있는 relu function의 사용이 필수적입니다.
'컴퓨터공학 💻 > 딥러닝' 카테고리의 다른 글
| [딥러닝] RNN 순환 신경망으로 영화 평론 감정 분석 예측기 만들기 (0) | 2021.08.06 |
|---|---|
| [딥러닝] RNN 순환 신경망(Recurrent Neural Networks) 이론 (0) | 2021.08.05 |
| [딥러닝] Keras 이용한 DNN 퍼셉트론 기본 모델 구현 (0) | 2021.08.05 |
| [딥러닝] DNN(Deep Neural Network) Perceptron 이론 (0) | 2021.08.05 |
| [딥러닝 기초이론] 클라우드 컴퓨팅 (Cloud Computing) (0) | 2021.08.04 |
Contents
소중한 공감 감사합니다